您现在的位置是:首页 > 技术人生 > 服务器相关服务器相关
Ubuntu 20.04 安装Hadoop 3.1.3集群
 高晓波2021-09-22【服务器相关】人已围观
高晓波2021-09-22【服务器相关】人已围观
简介1、环境准备
我这里准备了三台虚拟机,分别是vm-10、vm-11、vm-12,相应的host文件已经修改。10.11.99.218 vm-1010.11.99.195 vm-1110.11.99.163 vm-12
hadoop依赖于j
1、环境准备
我这里准备了三台虚拟机,分别是vm-10、vm-11、vm-12,相应的host文件已经修改。
hadoop依赖于jdk,所以这三台机器要安装jdk,我已经安装了jdk 1.8。
2、三台主机分别创建hadoop用户并设置密码
3、下载hadoop安装包
4、解压hadoop至/usr/local/目录下
修改权限
5、修改hadoop配置文件。Hadoop 的配置文件位于 /usr/local/hadoop-3.1.3/etc/hadoop/
(1)修改core-site.xml
(2)修改workers配置文件。
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),所以,在伪分布式配置时,就采用了这种默认的配置,使得节点既作为名称节点也作为数据节点。在进行分布式配置时,可以保留localhost,让Master节点同时充当名称节点和数据节点,或者也可以删掉localhost这行,让Master节点仅作为名称节点使用。
本教程让Master节点仅作为名称节点使用,因此将workers文件中原来的localhost删除,只添加如下一行内容:
(3)修改hdfs-site.xml配置
(4)修改yarn-site.xml 配置文件
(5)修改mapred-site.xml配置文件
(6)修改hadoop-env.sh,将export JAVA_HOME注释放开,修改为自己的jdk目录
将配置文件分发至其他两台主机
6、配置master免密登录slaver
必须要让Master节点可以SSH无密码登录到各个Slave节点上。首先,生成Master节点的公匙,如果之前已经生成过公钥,必须要删除原来生成的公钥,重新生成一次,因为前面我们对主机名进行了修改。具体命令如下:
其他节点收到公钥后操作
7、启动hadoop集群(master节点操作即可)
jps查看进程
Master中应该有以下4个进程
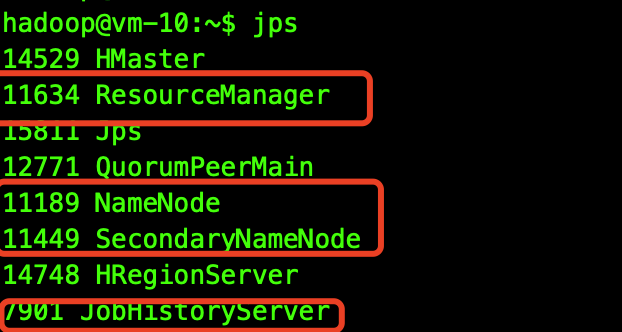
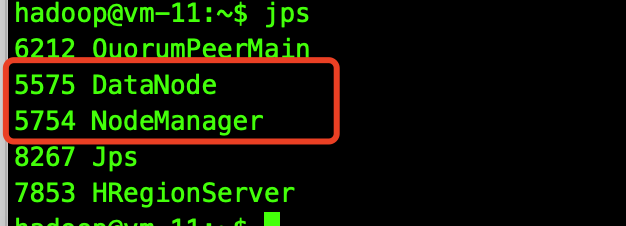
slave节点应该有以下2个进程
浏览器中输入地址http://vm-10:9870/,通过 Web 页面看到查看名称节点和数据节点的状态。如果不成功,可以通过启动日志排查原因。
参考文章:Hadoop集群安装配置教程_Hadoop3.1.3_Ubuntu
我这里准备了三台虚拟机,分别是vm-10、vm-11、vm-12,相应的host文件已经修改。
10.11.99.218 vm-10
10.11.99.195 vm-11
10.11.99.163 vm-12
hadoop依赖于jdk,所以这三台机器要安装jdk,我已经安装了jdk 1.8。
2、三台主机分别创建hadoop用户并设置密码
sudo useradd -r -m -s /bin/bash hadoop
sudo passwd hadoop
3、下载hadoop安装包
cd /usr/local/src
sudo wget https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
4、解压hadoop至/usr/local/目录下
tar -zxvf /usr/local/src/hadoop-3.1.3.tar.gz -C /usr/local/
修改权限
sudo chown -R hadoop /usr/local/hadoop-3.1.3
sudo chgrp -R hadoop /usr/local/hadoop-3.1.3
切换hadoop用户操作
su - hadoop
5、修改hadoop配置文件。Hadoop 的配置文件位于 /usr/local/hadoop-3.1.3/etc/hadoop/
(1)修改core-site.xml
vi /usr/local/hadoop-3.1.3/etc/hadoop/core-site.xml
添加配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm-10:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
(2)修改workers配置文件。
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),所以,在伪分布式配置时,就采用了这种默认的配置,使得节点既作为名称节点也作为数据节点。在进行分布式配置时,可以保留localhost,让Master节点同时充当名称节点和数据节点,或者也可以删掉localhost这行,让Master节点仅作为名称节点使用。
本教程让Master节点仅作为名称节点使用,因此将workers文件中原来的localhost删除,只添加如下一行内容:
vi /usr/local/hadoop-3.1.3/etc/hadoop/workers
vm-11
vm-12
(3)修改hdfs-site.xml配置
vi /usr/local/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm-10:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/data</value>
</property>
(4)修改yarn-site.xml 配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>vm-10</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(5)修改mapred-site.xml配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>vm-10:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>vm-10:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.3</value>
</property>
(6)修改hadoop-env.sh,将export JAVA_HOME注释放开,修改为自己的jdk目录
vi /usr/local/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8
将配置文件分发至其他两台主机
scp /usr/local/hadoop-3.1.3/etc/hadoop/* hadoop@vm-11:/usr/local/hadoop-3.1.3/etc/hadoop/
scp /usr/local/hadoop-3.1.3/etc/hadoop/* hadoop@vm-12:/usr/local/hadoop-3.1.3/etc/hadoop/
6、配置master免密登录slaver
必须要让Master节点可以SSH无密码登录到各个Slave节点上。首先,生成Master节点的公匙,如果之前已经生成过公钥,必须要删除原来生成的公钥,重新生成一次,因为前面我们对主机名进行了修改。具体命令如下:
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果已经存在)
ssh-keygen -t rsa # 执行该命令后,遇到提示信息,一直按回车就可以
将公钥发送到其他节点
scp ~/.ssh/id_rsa.pub hadoop@vm-11:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@vm-12:/home/hadoop/
其他节点收到公钥后操作
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在,则忽略本命令
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完以后就可以删掉
7、启动hadoop集群(master节点操作即可)
/usr/local/hadoop-3.1.3/sbin/start-all.sh
jps查看进程
Master中应该有以下4个进程
slave节点应该有以下2个进程
浏览器中输入地址http://vm-10:9870/,通过 Web 页面看到查看名称节点和数据节点的状态。如果不成功,可以通过启动日志排查原因。
参考文章:Hadoop集群安装配置教程_Hadoop3.1.3_Ubuntu
Tags:hadoop
很赞哦! ()
随机图文

centos7 手动编译安装 Nginx 1.18.0
工作中经常使用到nginx,本篇记录一下手工编译安装nginx过程
制作pve引导盘---U盘安装Proxmox VE(一)
年前搞了个星际蜗牛B款机箱,利用手头之前海淘dq77kb组装了个四盘位的Server。
Centos7 mysql5.7.25 tar包解压安装
1、mysql官网下载mysql-5.7.25-el7-x86_64.tar.gz[root@centos7 src]# wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.25-el7-x86_64.tar.gz 2、卸载系统
Centos7 安装Jenkins--Jenkins使用(一)
本文介绍了centos7环境下通过yum方式安装Jenkins过程

 微信收款码
微信收款码 支付宝收款码
支付宝收款码